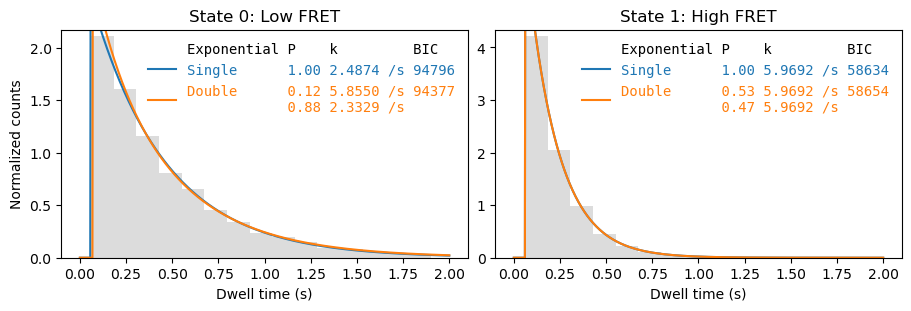
Histogram fit#
A common method of determining the reaction parameters is fitting the dwell time histogram with an exponential distribution:
To fit this function, we need the dwell time histogram in the form of the probability density function. To obtain it we normalize the histogram and divide by the bin width:
where \(N_{\text{total}}\) is the total number of dwell times and \(\Delta t_{\text{bin}}\) is the bin width.
[2]:
fig, axes = plt.subplots(1,2, figsize=(9,3), layout='constrained')
_ = file.analyze_dwells(method='histogram_fit', number_of_exponentials=[1,2], state_names={0: 'Low FRET', 1:'High FRET'},
plot=True, plot_dwell_analysis_kwargs=dict(plot_range=(0,2), axes=axes))
Bin size#
The fit result depends on the chosen bin width. The default ways of determining a proper bin width in numpy may not give good results for our data, mainly because our data is already binned in the time dimension with bin edges at the start and end of each frame.
[3]:
for bins in ['auto', 20, 'sturges']:
fig, axes = plt.subplots(1,2, figsize=(9,3), layout='constrained')
_ = file.analyze_dwells(method='histogram_fit', number_of_exponentials=[1,2], state_names={0: 'Low FRET', 1:'High FRET'},
fit_dwell_times_kwargs=dict(bins=bins), plot=True, plot_dwell_analysis_kwargs=dict(bins=bins, plot_range=(0,2), axes=axes))
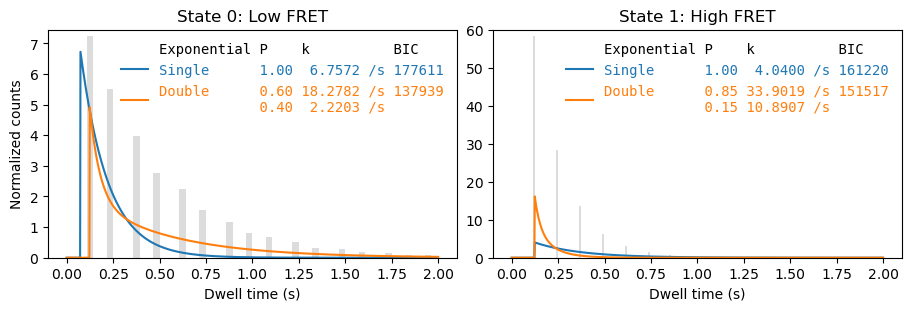


Hence we use a binning method that takes into account the frame interval by making the bin width a multiple of the frame interval \(\Delta t_{\text{frame}}\). To determine the number of multiples we estimate the bin width using the Freedman-Diaconis rule
and then round up to a integer number of the frame interval:
Additonally, the first bin starts at half the frame interval, so that the bin centers correspond to the time points of the frames.
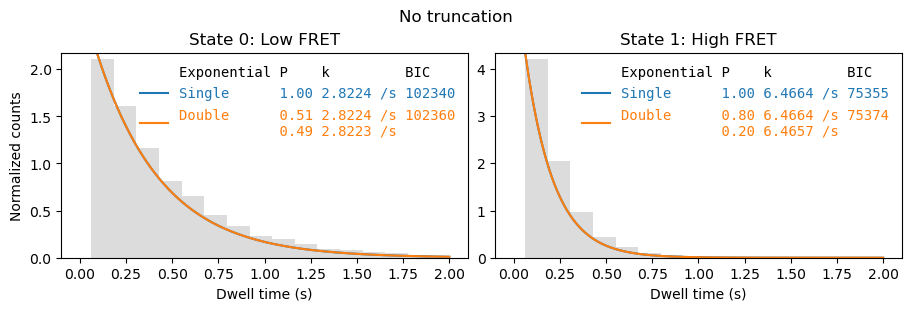
Truncation#
As we fit the probability density function, it is also important to use a truncated distribution.
[4]:
fig, axes = plt.subplots(1,2, figsize=(9,3), layout='constrained')
_ = file.analyze_dwells(method='histogram_fit', number_of_exponentials=[1,2], state_names={0: 'Low FRET', 1:'High FRET'},
truncation=(0, np.inf), fit_dwell_times_kwargs=dict(free_truncation_min=False),
plot=True, plot_dwell_analysis_kwargs=dict(plot_range=(0,2), axes=axes))
fig.suptitle('No truncation')
[4]:
Text(0.5, 0.98, 'No truncation')
[5]:
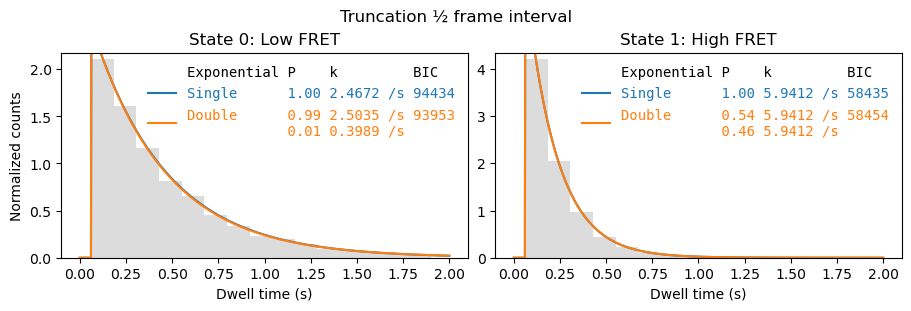
fig, axes = plt.subplots(1,2, figsize=(9,3), layout='constrained')
file.analyze_dwells(method='histogram_fit', number_of_exponentials=[1,2], state_names={0: 'Low FRET', 1:'High FRET'},
truncation=(file.cycle_time/2, np.inf), fit_dwell_times_kwargs=dict(free_truncation_min=False),
plot=True, plot_dwell_analysis_kwargs=dict(plot_range=(0,2), axes=axes))
_ = fig.suptitle('Truncation ½ frame interval')
We can also add the lower truncation value as an extra fit parameter:
[6]:
fig, axes = plt.subplots(1,2, figsize=(9,3), layout='constrained')
_ = file.analyze_dwells(method='histogram_fit', number_of_exponentials=[1,2], state_names={0: 'Low FRET', 1:'High FRET'},
truncation=(0, np.inf), fit_dwell_times_kwargs=dict(free_truncation_min=True),
plot=True, plot_dwell_analysis_kwargs=dict(plot_range=(0,2), axes=axes))
_ = fig.suptitle('Lower truncation value as free parameter')
